Pythonクローリング&スクレイピング リスト5.12でエラー

Pythonクローリング&スクレイピング[増補改訂版]―データ収集・解析のための実践開発ガイドーで勉強中
【リスト5.12 plot_historical_data.py-時系列データを可視化する】のところでエラーの沼にハマる。なんとか解決したため自分用メモを書いておく
xlrdで.xlsxが読み込めない
Pythonで.xlsファイルを読み込むライブラリとしては、xlrdが有名です。.xlsファイルと.xlsxファイルの両方を読み込めます。
Pythonクローリング&スクレイピング[増補改訂版]P186
と書いてあるがどうもxlrdの仕様が変わったようで、有効求人倍率のエクセル【第3表.xlsx】が読み込めない。手元で拡張子を.xlsに変えてとかやってみたがエクセルファイルのヘッダとかで.xlsxと認識されているのか結局同じエラー。
ImportError: Missing optional dependency 'openpyxl'. Use pip or conda to install openpyxl.これはエラーメッセージ通りopenpyxlを入れることで解決
pip install openpyxl参考

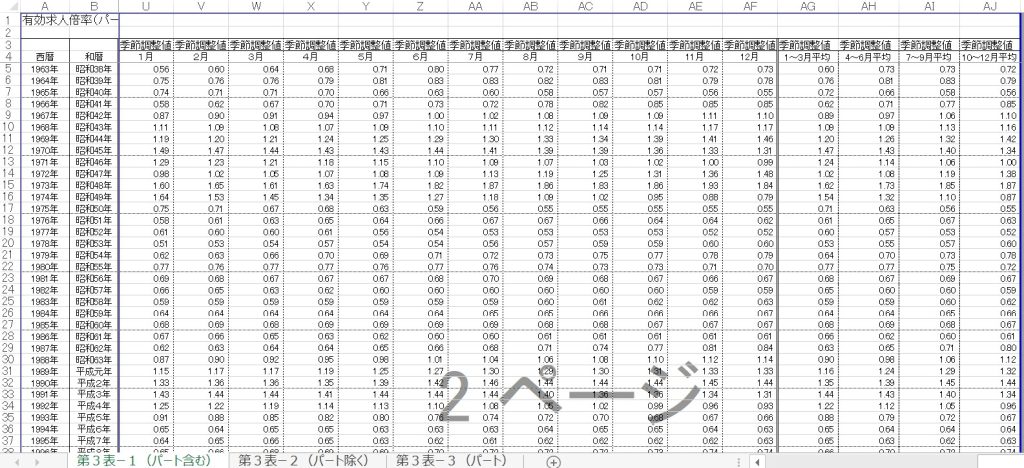
第3表.xlsxの形式が変わっている
読み込めたのはいいが今度はint(year[:-1])が数字じゃないと言われる。
/plot_historical_data.py", line 71, in parse_year_and_month
year = int(year[:-1]) #年を除去して数値に変換
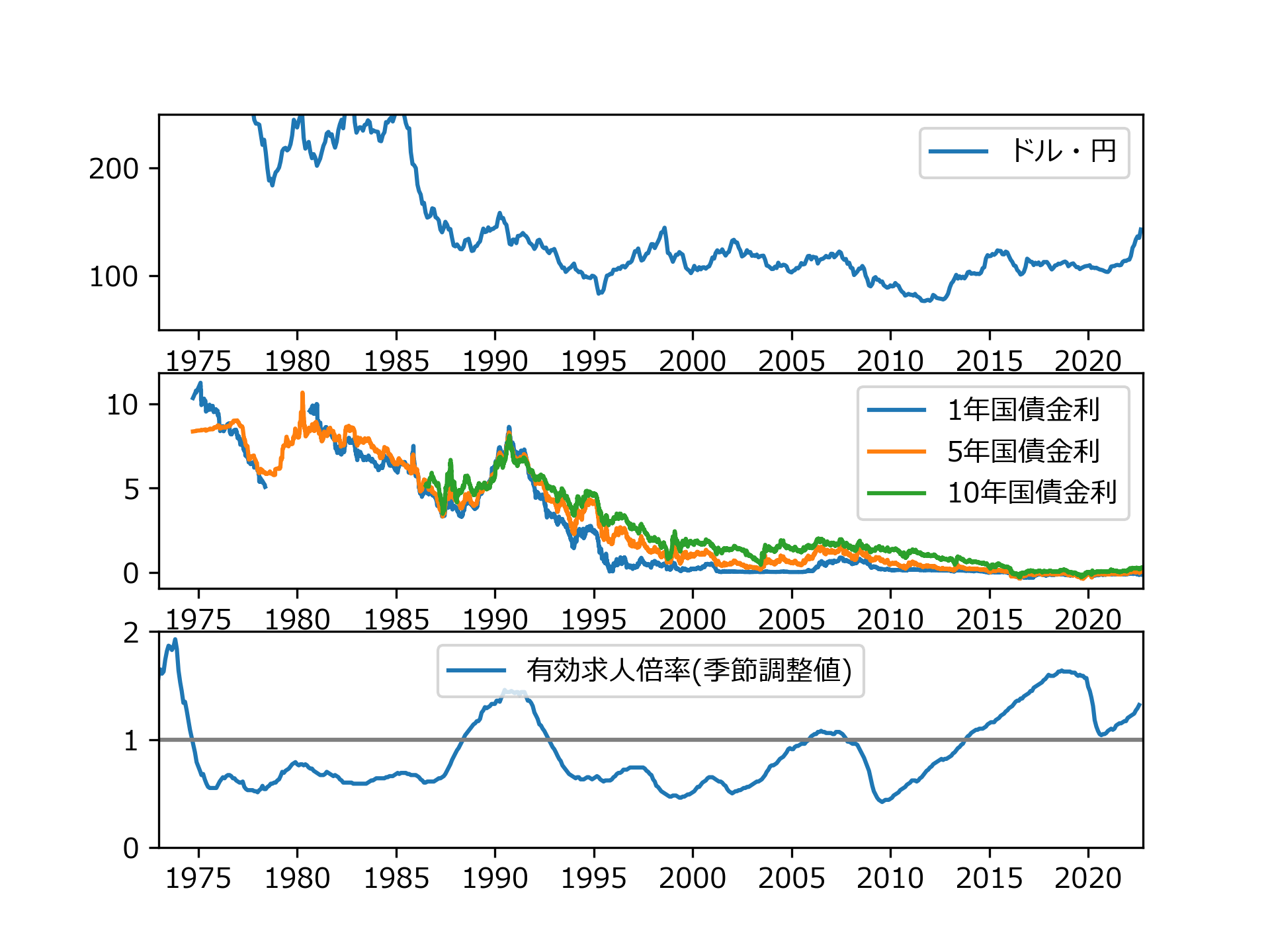
ValueError: invalid literal for int() with base 10: ''P187図5.9 ダウンロードしたExcelファイルの右下部分と比較して【第3表.xlsx】が変わっているんだよね。

なのでpandas.read_excel()のパラメーターを変えないと思ったように読み込めない。
比較して冒頭の3行と末尾の3行無視するのは同じなのでskiprows=3,skipfooter=3はそのまま。
usecolsが違う。西暦がA列、使いたいデータがU~AF列なのでusecols=’A,U:AF’に変更
# 書籍のコード17行目あたり
df_jobs = pd.read_excel('第3表.xlsx',skiprows=3,skipfooter=3,usecols='W,Y:AJ',index_col=0)
# 下のようにかえる
df_jobs = pd.read_excel('第3表.xlsx',skiprows=3,skipfooter=3,usecols='A,U:AF',index_col=0)さらに西暦が二桁’XX年’じゃなくてすべて四桁’19xx年’となっているためその変換処理がいらない
# 書籍のコード72行目あたり
year += (1990 if year >= 63 else 2000) #63年以降は19xx年、63年より前は20xx年とみなす
# いらないためコメントアウト(削除でもよい)
# year += (1990 if year >= 63 else 2000) #63年以降は19xx年、63年より前は20xx年とみなすここまで来たが5行目の | |倍|倍|倍|倍|…が邪魔
skiprowsかなにかで5行目をスキップできないか考えたがやり方がわからん。→できた
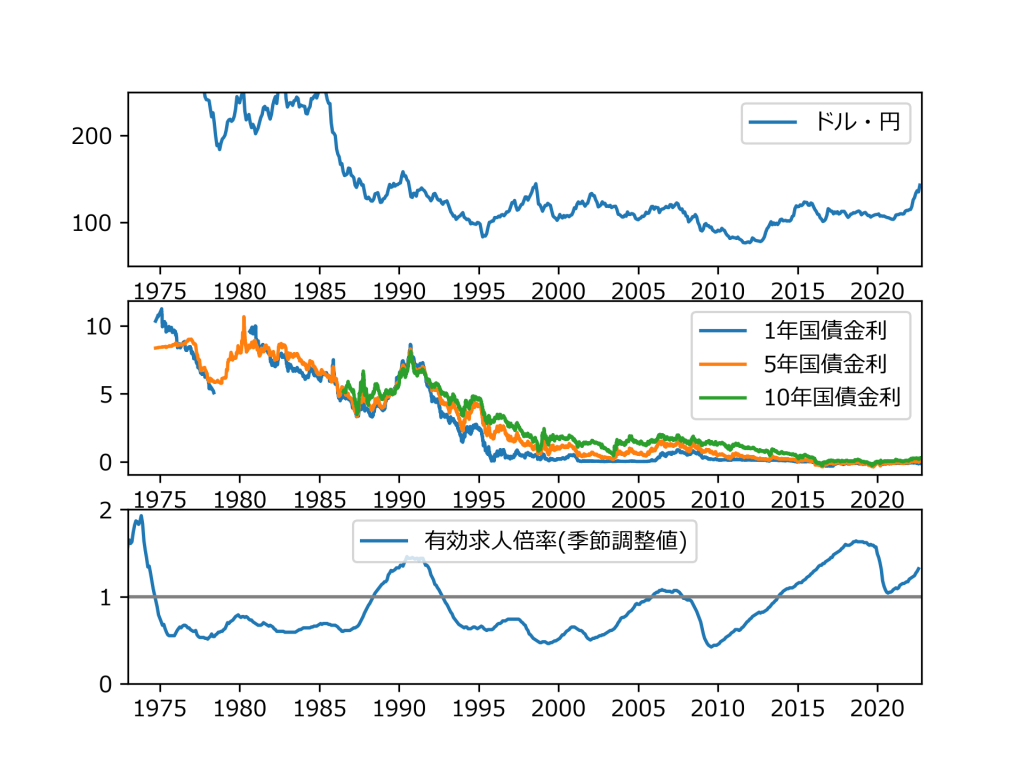
あんまり賢い方法じゃないがエクセルで5行目を削除して上書き保存。これで書籍のように欲しい結果が得られました。
追記 エクセルファイルをいじらなくても対策できた
skiprowsをリストで指定できる
ドキュメント等読んでみるとリストでskiprowsを指定できるみたい
# 1,2,3,5行目を無視する
pd.read_excel(skiprows=[0,1,2,4]なので冒頭の3行と5行目をスキップするために下記のように書き換えればOK
# 書籍のコード17行目あたり
df_jobs = pd.read_excel('第3表.xlsx',skiprows=3,skipfooter=3,usecols='W,Y:AJ',index_col=0)
# 下のようにかえる
df_jobs = pd.read_excel('第3表.xlsx', skiprows=[0,1,2,4],
skipfooter=3, usecols='A,U:AF', index_col=0)無理やりエクセルファイルで行削除したりせずに対応できました

コメント