リスト5.25 get_note_contents.pyが動かない

本の通り書いたのに動かないと素人は大慌てですよ。
noteのサイトかなり変わってるンだわ
そもそも本に書いてあるhttps://note.muじゃなくてhttps://note.comだし。まあこれはリダイレクトされるからいいとするけど、CSS Selectorももちろん変わっているわけで。
まずはCSS Selectorがどうなっているのか?みんな大好きDev toolでみてみよう。
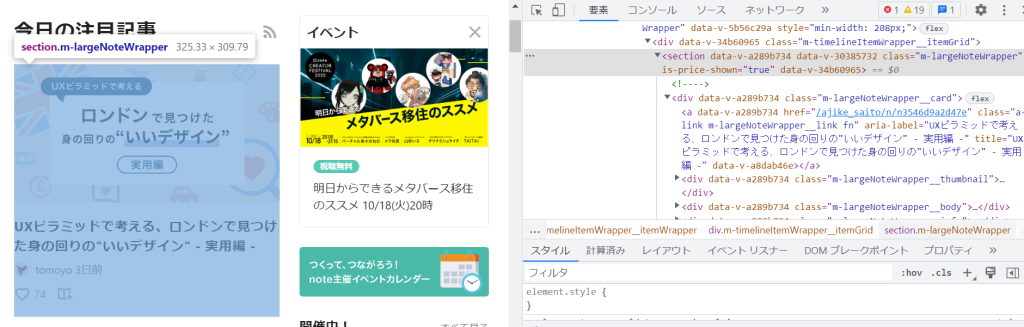
<section class="m-largeNoteWrapper">
<div class="m-largeNoteWrapper__card">
<a href="リンクurl" class="a-link m-largeNoteWrapper__link fn"></a>
<div class="m-largeNoteWrapper__thumbnail">
<div class="m-thumbnail m-thumbnail--large">
<img class="a-image m-thumbnail__image lazyloaded" />
</div>
</div>
<div class="m-largeNoteWrapper__body">
<div class="m-noteBody m-noteBody--large is-no-description">
<h3 class="m-noteBody__title">タイトル</h3>
</div>
</div>
<div class="m-largeNoteWrapper__info">
<div class="o-largeNoteSummary__info">
<div class="o-largeNoteSummary__userWrapper">
<a href="ユーザーのリンク" class="a-link o-largeNoteSummary__user fn">
<div
class="m-avatar o-largeNoteSummary__avatar m-avatar--smallXsmall"
>
<img
src="ユーザーの画像"
class="a-image m-avatar__image lazyloaded"
/>
</div>
<span class="o-largeNoteSummary__userName"> ユーザー名 </span></a
>
</div>
<div class="o-largeNoteSummary__date">3日前</div>
</div>
</div>
<div class="m-largeNoteWrapper__action">
<div class="o-largeNoteSummary__action">
<div>
<div class="o-noteAction">
<div class="o-noteAction__item">
<div class="o-noteAction__like">
<span class="o-noteLikeV3"
><span class="o-noteLikeV3__iconContainer"
><button
aria-label="スキ"
class="o-noteLikeV3__icon a-icon a-icon--heart a-icon--size_mediumSmall"
></button>
</span>
</span>
<span class="o-noteAction__likeCount">
<!-- スキの数 -->74
</span>
</div>
</div>
<div class="o-magazineAdd o-noteAction__item">
<button
aria-label="記事を保存"
class="a-icon a-icon--magazineAdd a-icon--size_mediumSmall"
></button>
</div>
</div>
</div>
</div>
</div>
</div>
</section>余計な属性削ったり、かなり簡略化してもこんなに長いからつらい。
要は<section class="m-largeNoteWrapper">のなかに
欲しいURL:<a class="a-link m-largeNoteWrapper__link fn"
href="https://note.com/ユーザー名/n/記事id">があり
欲しいtitle:<h3 class="m-noteBody__title">があり
欲しいスキ:<span class="o-noteAction__likeCount">があるdescriptionは無くなったっぽいので取得しないようにしました。
読み込み時間待ってあげないと何も取得できない
リダイレクトのせいかと思ったけど、driver.get(‘https://note.com/’)に変えても普通にsleep入れないと何も取得できない。書いた人はテスト段階でsleep無しで動いたのは、超絶ハイスペックPCなのか?というか超絶ハイスペックPCでもボトルネックは通信速度だよね?とか思いながら、sleepを追加
# importを追加
import time
# 20行目あたりトップページを読み込むsleepを追加
navigate(driver)
time.sleep(5)seleniumのバージョン4.3.0から、find_element_by_*系のメソッドが廃止されて使えなくなった。
2022年6月24日にアップデートされたみたいで、比較的最近変わったみたいですね。書き方をそれに合わせないといけない。
まずimport文を追加して
from selenium.common.exceptions import NoSuchElementException
#コード5行目あたり インポート文を追加
from selenium.webdriver.common.by import ByさらにCSS Selectorを上で書いた新しいのに変えてSeleniumの新しい書き方に合わせて書く
# コード50行目あたり
# コンテンツを表す×div→○section要素について反復する
for section in driver.find_elements(By.CSS_SELECTOR, '.m-largeNoteWrapper'):
a = section.find_element(
By.CSS_SELECTOR, '.m-largeNoteWrapper__link')参考

スキの取得でエラー出まくり
4桁数字にカンマ入るためint()で括るとエラー
これも最初何が悪いか分からなかったけど、スキの数が4桁超えるとカンマが入っていた。まあ読みやすいのはいいんだけど、int(1,000)でエラー出るンだわ。
int()で括っているの削除しようかとも思ったけど、よくあることのようでググったらすぐ解決方法でてきた。
int(1,000).replace(',', '')これで解決
下のほうのスキはCSS Selectorが違う
ハートに色つけるためなのか何かわからないけど下の方のスキ数が取得出来なくて、.textの中身がないと怒られるのよ。
ちょうど本に書いてあった、画像コンテンツなど概要がないときにNoSuchElementExceptionでdescription= ‘ ‘にしたのが使えると考えて、スキ:<span class=”o-noteAction__likeCount”>で取得できずエラー出るときにNoSuchElementExceptionで下の方のCSS Selector “.m-noteBody__statusLabel”から取得するとした。
# scrape_contents()を以下のように変える
# コンテンツを表すsection要素について反復する
for section in driver.find_elements(By.CSS_SELECTOR, '.m-largeNoteWrapper'):
a = section.find_element(
By.CSS_SELECTOR, '.m-largeNoteWrapper__link')
try:
# いいね4桁超えるとカンマ入るためint()だとエラー出るのでreplace()
like = int(section.find_element(By.CSS_SELECTOR,
'.o-noteAction__likeCount').text.replace(',', ''))
except NoSuchElementException:
# 下の方のいいね数は <div class="m-noteBody__statusLabel">274</div>
like = int(section.find_element(By.CSS_SELECTOR,
'.m-noteBody__statusLabel').text.replace(',', ''))
# URL、タイトル、スキの数を取得してdictとしてリストに追加する
contents.append({
'url': a.get_attribute('href'),
'title': section.find_element(By.TAG_NAME, 'h3').text,
'like': like,
})
return contentstry exceptをif else的に使うのは違うような気がするけど、他に解決がわからないためとりあえずこれで。
以上なんとか解決できました。
自分であーだこーだやって何かプログラミング出来る人になっているような気がしました。はい。


コメント